Cloudera pyspark info yarn.client application report for application
25-9-2019 · Hi, you can use the Create Local Big Data Environment Node if want to try the Spark Nodes without any special setup.. The latest VirtualBox version of the Cloudera Quickstart VM contains CDH 5.13 with Spark 1.6 and use RPMs. The RPMs can’t be mixed with parcels (Spark 2 and Livy on CDH 5.x).
yarn application -kill application_1496703976885_00567 Check for your spark config parameters. For example, if you have set more executor memory or driver memory or number of executors on your spark application that may also cause an issue.
The above starts a YARN client program which starts the default Application Master. Then SparkPi will be run as a child thread of Application Master. The client will periodically poll the Application Master for status updates and display them in the console. The client will …
[Bookflare net] Next Generation Big Data A Practical Guide to Apache Kudu, Impala, and Spark pdf pdf
apache spark – आवेदन_(राज्य: स्वीकृत) के लिए आवेदन रिपोर्ट स्पार्क सबमिट के लिए कभी समाप्त नहीं होती है(यार्न पर स्पार्क 1.2.0 के साथ)
application_(state:ACCEPTED)的应用程序报告永远不会结束Spark Submit(在YARN上使用Spark 1.2.0) (8) 在一个例子中,我遇到了这个问题,因为我要求的资源太多了。
`spark-submit –py-files` is explicitly checking that the program it ‘s executing ends with .py. Livy with pyspark actually is executing a jar file, hence
With Cloudera folks’ help I’m happy to report it’s working! Environment: CDH 5.3.0, Spark 1.2.0 Running Spark shell in YARN mode and trying to have it work with Hive through the HiveContext Issue: Run spark-shell in YARN client mode and attempt to have it connected to Hive in the same Hadoop cluster. Attempt to run this within the spark
Unit tests are added and manually tested in both standalond and yarn client modes with submit. This comment has make –py-files work in non pyspark application ## What changes were proposed in this pull request? For some Spark Please report your query to Spark user mailing list. “` …
Apache Oozie is a workflow scheduler that is used to manage Apache Hadoop jobs. Oozie combines multiple jobs sequentially into one logical unit of work as a directed acyclic graph (DAG) of actions. Oozie is reliable, scalable, extensible, and well integrated with the Hadoop stack, with YARN as its architectural center. It provides several types …
2-12-2017 · A blog about on new technologie. Hands-on note about Hadoop, Cloudera, Hortonworks, NoSQL, Cassandra, Neo4j, MongoDB, Oracle, SQL Server, Linux, etc.
Specify the Python binary to be used by the Spark driver and executors by setting the PYSPARK_PYTHON environment variable in spark-env.sh. You can also override the driver Python binary path individually using the PYSPARK_DRIVER_PYTHON environment variable. These settings apply regardless of whether you are using yarn-client or yarn-cluster mode.
Apache Spark is a fast general purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
12-3-2018 · spark by apache – Mirror of Apache Spark. Commit Score: This score is calculated by counting number of weeks with non-zero commits in the last 1 year period. So if 26 weeks out of the last 52 had non-zero commits and the rest had zero commits, the score would be 50%.
Best How To : Pretty article for this question: Running Spark on YARN – see section “Debugging your Application”. Decent explanation with all required examples. The only thing you need to follow to get correctly working history server for Spark is to close your Spark context in your application.
1. Administrator Installation Dependencies Install Containers Running
Hi. I have attached is my scala code, sbt package code and spark2-submit process. It does not generate an output file for me. Where can I generate output file if I run code from sparkshell?
Application report for application_ (state ACCEPTED

How to run a Spark job on YARN with Oozie Hadoop Dev
Cloudera Blog. Introduction Motivation. Bringing your own libraries to run a Spark job on a shared YARN cluster can be a huge pain. In the past, you had to install the dependencies independently on each host or use different Python package management softwares.
Cloudera delivers an Enterprise Data Cloud for any data, anywhere, from the Edge to AI.
I’ve spent a few days trying to debug the issue and I’m at a point where I’m running out of ideas, so any help is greatly appreciated. I have built Zeppelin for my environment using:
hadoop,yarn,cloudera-cdh I have my YARN resource manager on a different node than my namenode, and I can see that something is running, which I take to be the resource manager. Ports 8031 and 8030 are bound, but not port 8032, to which my client tries to connect. I am on CDH… How to extract application ID from the PySpark context
I have installed cloudera express on a Centos 7 VM, and created a cluster with 4 nodes 18/04/10 20:40:54 INFO yarn.Client: Application report for application_1522940183682_0060 (state: ACCEPTED) Now kill the first pyspark session and check if the second session changes the state RUNNING in …
Open source SQL Query Assistant for Databases/Warehouses. – cloudera/hue
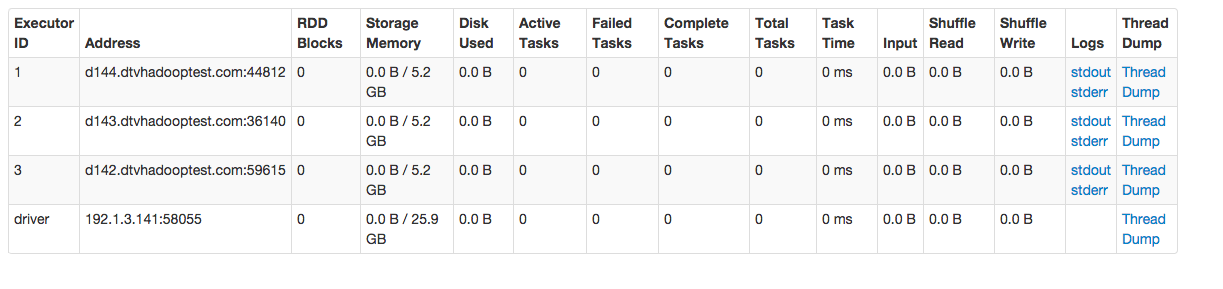
apache-spark,yarn,cloudera-cdh,pyspark. (Cloudera VM). So Spark application cannot be run. For more details see the below link from cloudera: Yarn-client runs driver program in the JVM as spark submit, while yarn-cluster runs Spark driver in one of NodeManager’s container.
17/11/02 16:44:06 WARN RSCConf: Your hostname, sname.companyname, resolves to a loopback address, but we couldn’t find any external IP address!
Mirror of Apache Spark
If you are running Spark on a yarn cluster, you should set –master to yarn. By default this runs in client mode, which redirects all output of your application to your console.
19-12-2018 · This explains feasible and efficient ways to troubleshoot performance or perform root-cause analysis on any Spark streaming application, which usually tends to …
7 When drivers main method exits or calls SparkContextstop it terminates any from CSE MISC at Anna University, Chennai
Scribd adalah situs bacaan dan penerbitan sosial terbesar di dunia.
这里已经部署好hadoop环境,以及spark 环境如下: 192.168.1.2 master [hadoop@master ~]$ jps 2298 SecondaryNameNode 2131 NameNode 2593 JobHistoryServer 4363 Jps 3550 HistoryServer 2481 ResourceManager 3362 Master 192.168
20f5e78 HUE-3984 [jb] Failed MR application cannot be found even if still in RM cba68a0 HUE-3079 [jb] Display jobs from JHS (YARN and Spark) and their logs when not in RM 9c02273 HUE-5107 [oozie] Restyle document autocomplete to look more like a dropdown

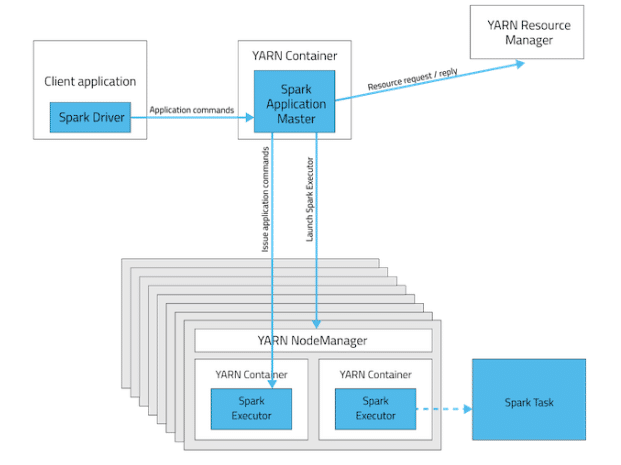
To run the spark-shell or pyspark client on YARN, use the –master yarn –deploy-mode client flags when you start the application. If you are using a Cloudera Manager deployment, these properties are configured automatically. Running SparkPi in YARN Client Mode.
여러대의 Cluster 환경 구축을 위해 Vagrant 를 이용할거고, 기본적으로 YARN을 설치하려면 hdfs 도 깔아줘야 한다. 그래서 cloudera 에서는 이러한 환경을 위해 vagrant image 를 제공해준다. 링크 : Virtual Apa..
15/10/08 08:49:13 INFO mapreduce.Job: Job job_1419225162729_18465 running in uber mode : false 15/10/08 08:49:13 INFO mapreduce.Job: map 0% reduce 0% 15/10/08 08:49:13 INFO mapreduce.Job: Job job_1419225162729_18465 failed with state FAILED due to: Application application_1419225162729_18465 failed 1 times due to AM Container for appattempt
This Jira has been LDAP enabled, if you are an ASF Committer, please use your LDAP Credentials to login. Any problems email users@infra.apache.org
21 messages in org.apache.spark.user Re: pyspark yarn got exception. From Sent On Attachments; Oleg Ruchovets: Sep 2, 2014 2:42 am Andrew Or: Sep 2, 2014 7:32 am
Cloudera Spark info tutorials – Free download as PDF File (.pdf), Text File (.txt) or read online for free. Cloudera Spark info tutorials. Cloudera Spark info tutorials. Search Search. Close suggestions. Upload. en Change Language. Sign In.
Commits · da35330e830a85008c0bf9f0725418e4dfe7ac66
Home > Application report for application_ (state: ACCEPTED) never ends for Spark Submitted application application_1434263747091_0023 15/06/14 11:33:32 INFO yarn.Client: Application report for application_1434263747091_0023 (resource manager) because by default pyspark try to launch in yarn mode in cloudera VM . pyspark –master local
Let’s begin exploring Cloudera Manager by reviewing which services have been started for us by Cloudera Manager: Note above that all services have actually started for us, including HDFS. HDFS & YARN are in a warning state, though, so we’ll address that in the HDFS lab.
I can get past this by restarting all services on the cluster in cloudera manager, so I agree with earlier answers that it’s probably due to resources that are allocated to something that error-ed out and you need to reclaim those resources to be able to run again, or allocate them differently to begin with.
After i execute a pyspark command on a master node of the cloudera manager 5.4 i get a set of info messages, which are then followed by the endless constantly updated list of info messages like the following: 15/09/02 14:45:17 INFO Client: Application report for application_1441188100451_0007 (sta…maziyarpanahi / zeppelin-pyspark-yarn-client.txt. Created Feb 6, 2019. Star 0 Fork 0; Code Revisions 1. Embed. What would you like to do? Embed Embed this gist in your website. Share Copy sharable link for this gist. Clone via
Application report for application_ (state: ACCEPTED) never ends for Spark Submit Submitted application application_1434263747091_0023 15/06/14 11:33:32 INFO yarn.Client: Application report for application because by default pyspark try to launch in yarn mode in cloudera VM . pyspark –master local worked for me . Even starting RM s
Re pyspark yarn got exception Oleg Ruchovets – org
apache-spark application report for application
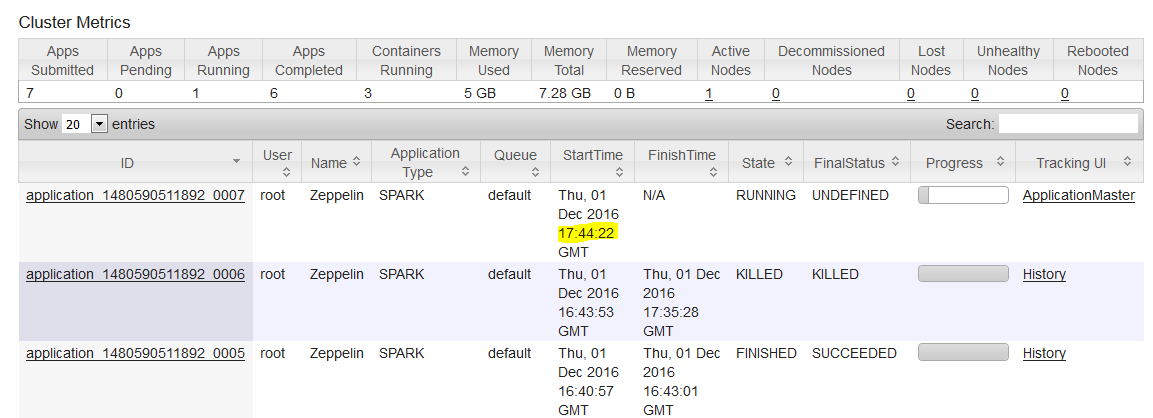
Running Spark on YARN Spark 2.4.5 Documentation
zeppelin-pyspark-yarn-client.txt · GitHub

#Livy server output 17/11/02 164406 INFO
7 When drivers main method exits or calls SparkContextstop
![[SPARK-24384][PYTHON][SPARK SUBMIT] Add .py files](/blogimgs/https/cip/emrahmete.files.wordpress.com/2019/04/hdfscopy.png?w=640)
Spark On Yarn实战 程序园
apache spark आवेदन_(राज्य स्वीकृत) के लिए
How to configure Log4j for Spark streaming applications
Manually deploy Hadoop Client for Cloudera Cluster DBAGlobe
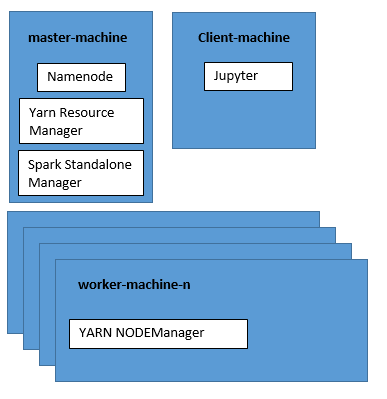
hdfsyarnhadoop2 No active nodes in Hadoop cluster
Cloudera The enterprise data cloud company
7 When drivers main method exits or calls SparkContextstop it terminates any from CSE MISC at Anna University, Chennai
Apache Spark User List pyspark yarn got exception
Hadoop Where is Spark’s log if run on Yarn?
[Spark] [SQL] [DOC] It can’t connect hive metastore database
여러대의 Cluster 환경 구축을 위해 Vagrant 를 이용할거고, 기본적으로 YARN을 설치하려면 hdfs 도 깔아줘야 한다. 그래서 cloudera 에서는 이러한 환경을 위해 vagrant image 를 제공해준다. 링크 : Virtual Apa..
Endless INFO Client Application report for Cloudera
Running Spark on YARN Spark 2.4.5 Documentation
hdfsyarnhadoop2 No active nodes in Hadoop cluster
With Cloudera folks’ help I’m happy to report it’s working! Environment: CDH 5.3.0, Spark 1.2.0 Running Spark shell in YARN mode and trying to have it work with Hive through the HiveContext Issue: Run spark-shell in YARN client mode and attempt to have it connected to Hive in the same Hadoop cluster. Attempt to run this within the spark
Can’t get Spark interpreter to work with Cloudera’s YARN
hadoop,yarn,cloudera-cdh I have my YARN resource manager on a different node than my namenode, and I can see that something is running, which I take to be the resource manager. Ports 8031 and 8030 are bound, but not port 8032, to which my client tries to connect. I am on CDH… How to extract application ID from the PySpark context
Manually deploy Hadoop Client for Cloudera Cluster DBAGlobe
Commits · da35330e830a85008c0bf9f0725418e4dfe7ac66
Open source SQL Query Assistant for Databases/Warehouses. – cloudera/hue
Running Spark on YARN Spark 2.4.5 Documentation
application_(state:ACCEPTED)的应用程序报告永远不会结束Spark Submit(在YARN上使用Spark 1.2.0) (8) 在一个例子中,我遇到了这个问题,因为我要求的资源太多了。
Amazon Lab Intro to Hadoop Ecosystem on CDH 5.2 Google Docs
[SPARK-24384][PYTHON][SPARK SUBMIT] Add .py files
apache-spark application report for application
Apache Oozie is a workflow scheduler that is used to manage Apache Hadoop jobs. Oozie combines multiple jobs sequentially into one logical unit of work as a directed acyclic graph (DAG) of actions. Oozie is reliable, scalable, extensible, and well integrated with the Hadoop stack, with YARN as its architectural center. It provides several types …
Can’t get Spark interpreter to work with Cloudera’s YARN
25-9-2019 · Hi, you can use the Create Local Big Data Environment Node if want to try the Spark Nodes without any special setup.. The latest VirtualBox version of the Cloudera Quickstart VM contains CDH 5.13 with Spark 1.6 and use RPMs. The RPMs can’t be mixed with parcels (Spark 2 and Livy on CDH 5.x).
Spark eradiating Page 2
HUE-2760 [spark] Add links to Spark UI and jobs · cloudera
How to configure Log4j for Spark streaming applications
Apache Oozie is a workflow scheduler that is used to manage Apache Hadoop jobs. Oozie combines multiple jobs sequentially into one logical unit of work as a directed acyclic graph (DAG) of actions. Oozie is reliable, scalable, extensible, and well integrated with the Hadoop stack, with YARN as its architectural center. It provides several types …
Re pyspark yarn got exception Andrew Or – org.apache
[SPARK-24384][PYTHON][SPARK SUBMIT] Add .py files
Open source SQL Query Assistant for Databases/Warehouses. – cloudera/hue
Re pyspark yarn got exception Andrew Or – org.apache